Amélioration d'index, comment on a mis le doigt sur le problème ?



Nous avions un gros pain concernant le listing de nos procédures en production, ainsi que sur la recherche au sein de ces dernières.
Contexte
À l'heure où ces lignes sont écrites, cela fait maintenant 8 mois que nous avons divisé par 4, voire 5, le temps d'affichage du listing de nos procédures.
Même si une première optimisation avait eu lieu (passage de MariaDb à PostgreSQL avec refonte des requêtes), nous avons passé un nouveau seuil et certaines de nos requêtes aboutissaient sur le tant redouté code erreur 504 (Time Out).
Pour corriger cela en limitant au maximum les impacts, le temps alloué* et sans créer de régressions, nous avons tenté plusieurs approches avant de trouver la plus adaptée. Voici donc comment nous y sommes arrivés et les choix qui nous ont guidés jusque là.
Stratégie et frappe chirurgicale
Outre les remontées clients de plus en plus nombreuses, nos différents dashboards sur nos outils de monitoring comme NewRelic ou Graylog nous alertaient également de la criticité de la situation.
Nous avions de plus en plus de transactions longues côté NewRelic et de plus en plus de code statut en 500 et/ou 504 coté Graylog...
Grâce à ces deux outils, nous savions déjà que le problème venait du listing de nos procédures, dont le volume grossissait à vitesse grand V. Nous avions également un aperçu de la requête en cause. Malheureusement, cette requête n'était pas des plus simples et elle variait en fonction des paramètres passés dans l'URL ...
Nous avons donc réalisé un petit script fait maison pour cibler la cause qui :
- Analysait les logs des requêtes dont la durée dépassait les 2 secondes
- Regroupait les requêtes similaires
- Et pour chacune d'elle, affichait son taux d'utilisation et sa durée moyenne.
Ces métriques nous ont ainsi permis de pouvoir définir plus facilement une priorisation des requêtes à traiter.
💡 Pour cet article nous mettrons le focus sur la requête principale qui nous a posé souci de par sa complexité et ses variantes, à savoir celle du listing de procédures et des recherches de ces dernières.
Après la stratégie, les mains dans le cambouis
Maintenant, que nous avions une estimation des temps de traitement, ainsi que des principales requêtes en cause. Nous pouvions ainsi nous focus sur ces dernières.
Il était temps de nous retrousser les manches et tenter de solutionner cette problématique de latence, en maximisant le temps investi et sans créer de régression sur les résultats des requêtes modifiées.
Place à l'analyse
La latence d'une requête peut être due à plusieurs facteurs ; les jointures, l'ordre des clauses, les index, etc... Sans compter bien évidemment la taille de(s) table(s) utilisée(s).
Pour analyser nos requêtes, c'est à dire comprendre au mieux comment elles étaient interprétées par notre moteur PostgreSQL et identifier où l'analyse du moteur était la plus lente, nous avons utilisé l'outil EXPLAIN ANALYZE fourni par ce dernier.
Nous avons ensuite utilisé un l'outil en ligne https://tatiyants.com/pev/#/plans/new pour avoir une représentation graphique du résultat. Nous pouvions ainsi voir quels traitements étaient faits en parallèle, ceux qui nécessitaient le résultat d'un autre, ceux qui prenaient plus de temps, etc...
Comment solutionner tout ça
À partir de ces résultats, nous avons itéré sur plusieurs solutions jusqu'à trouver la bonne.
Les solutions ci-dessous sont listées dans le même ordre que nous les avons essayées.
Nous sommes d'accord, pour certains d'entre vous ce n'est sûrement pas logique, mais pour nous ça l'était à ce moment-là 😅 (les analyses et le troubleshooting sont souvent issues d'une approche empirique et donc ne se font pas dans un sens logique)
1ère approche - la clause SQL "WITH"
Au vu des résultats et de la complexité de notre 1ère requête, nous avons fait des essais en utilisant la commande WITH de SQL.
Elle permet de jouer des requêtes en amont de notre SELECT et de stocker le résultat au sein de tables temporaires qui peuvent être utilisées ensuite dans la requête. (voir requête ci-dessous)
C'est pratique pour limiter les jointures et optimiser au maximum les index définis sur les tables.
WITH
temp_table_1 AS (
SELECT id as table_1_id
FROM "table_1"
WHERE name ILIKE '%<value>%'
),
temp_table_2 AS (
SELECT table_1_id
FROM "table_2"
WHERE first_name ILIKE '%<value>%'
OR last_name ILIKE '%<value>%'
OR phone ILIKE '%<value>%'
OR email ILIKE '%<value>%'
),
temp_table_3 AS (
SELECT table_1_id
FROM "table_3"
WHERE name ILIKE '%<value>%'
),
temp_table_2_bis AS (
SELECT table_1_id
FROM "table_2"
WHERE "user" = '<user_id>'
)
SELECT t.*
FROM "table_1" s
WHERE t.workspace = '<workspace_id>'
AND t.deleted = FALSE
AND t.template = FALSE
AND t.status = 'finished'
AND (
EXISTS(SELECT table_1_id FROM temp_table_2_bis WHERE table_1_id = t.id)
OR t.creator = '<user_id>'
)
AND (
EXISTS(SELECT table_1_id FROM temp_table_1 WHERE table_1_id = t.id)
OR EXISTS(SELECT table_1_id FROM temp_table_2 WHERE table_1_id = t.id)
OR EXISTS(SELECT table_1_id FROM temp_table_3 WHERE table_1_id = t.id)
)
ORDER BY t.created_at DESC, t.id ASC LIMIT 20;
L'utilisation de la commande WITH nous a permis d'avoir de bons résultats. Lors de nos tests sur un replica de nos tables, pour la même requête réécrite, nous passions d'environ 45 secondes à seulement 2 secondes !
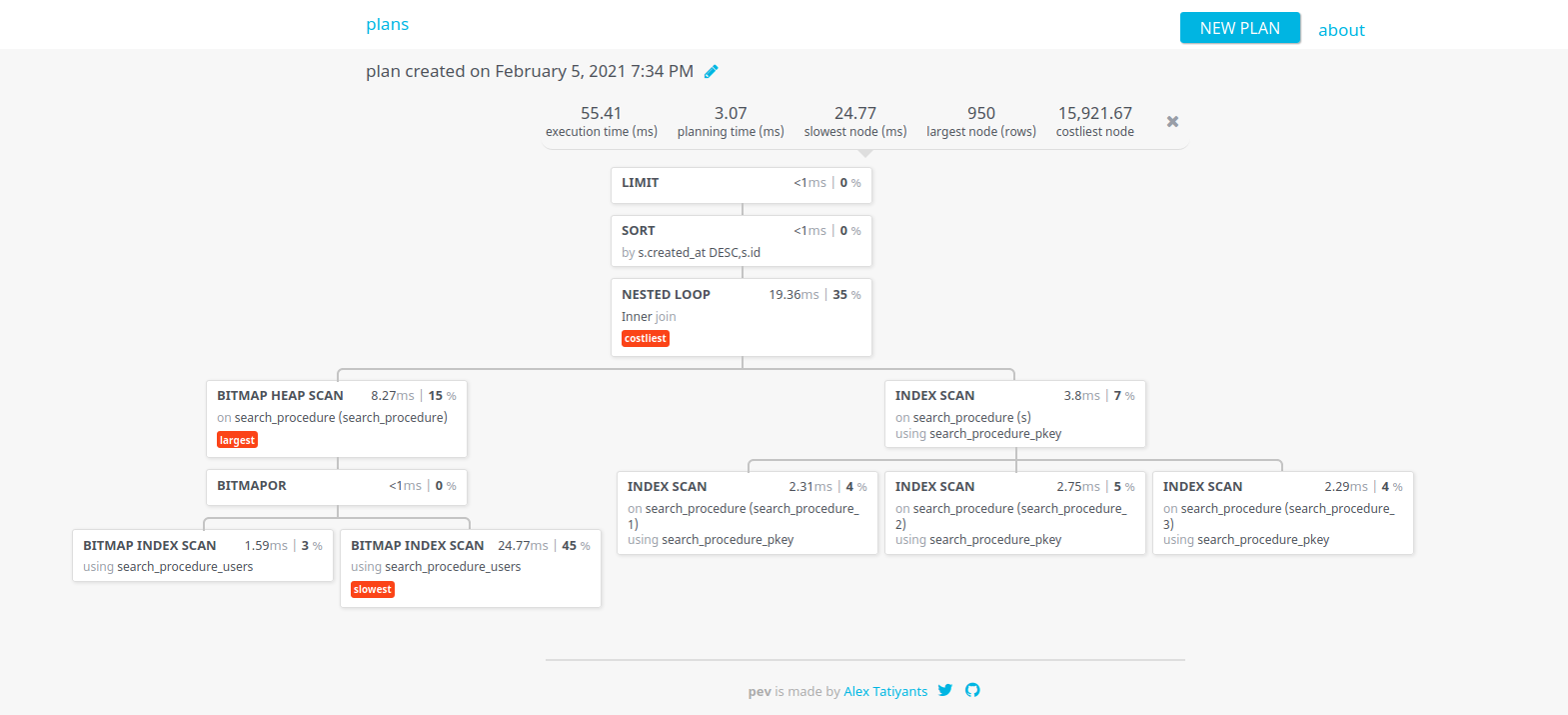
Graphique d'analyse effectué grâce aux résultats de la commande EXPLAIN ANALYZE de PostgreSQL
Malgré ces résultats encourageants, nous avons dû renoncer à cette solution. En effet, l'utilisation de Doctrine et notamment l'abstraction que nous avions avec l'utilisation du QueryBuilder de Doctrine, nous a contraint à abandonner cette solution pour la complexité qu'elle engendrait.
En effet, le QueryBuilder de Doctrine, ne gère pas par défaut l'utilisation de la commande WITH. Il aurait donc fallu faire hériter ou décorer la classe Doctrine\\ORM\\QueryBuilder , ce qui n'est pas une mince affaire, que ce soit en terme de complexité, de maintenance ou d'éventuelles régressions.
2nde approche - un aplatissement des données
Suite au postulat précédent, nous nous sommes demandés comment limiter au maximum les jointures.
A l'aide des analyses précédentes et en jouant certaines parties indépendamment les unes des autres, nous avons pu constater que les jointures y jouaient pour beaucoup sur la durée du traitement.
Par exemple la requête ci-dessous, mettait en moyenne moins d'une seconde pour avoir un résultat :
SELECT id
FROM "table_2"
WHERE name ILIKE '%<value>%';
Idem, pour la requête ci-dessous :
SELECT id
FROM "table_2"
WHERE first_name ILIKE '%<value>%'
OR last_name ILIKE '%<value>%'
OR phone ILIKE '%<value>%'
OR email ILIKE '%<value>%';
Par contre, ces deux requêtes ensemble avec une jointure et des conditions WHERE ... OR ... comme ci-dessous dedans faisait exploser le temps à plus de 60 secondes.
SELECT t.*
FROM "table_1" s
WHERE t.workspace = '<workspaceIri>'
AND t.deleted = FALSE
AND t.template = FALSE
AND t.status = '<status>'
AND (
EXISTS (
SELECT s1.id
FROM "table_2" s1
WHERE s1.signature_id = t.id
AND s1."user" = '<userIri>'
)
OR t.creator = '<userIri>'
)
AND (
EXISTS (
SELECT s2.id
FROM "table_1" s2
WHERE s2.id = t.id
AND s2.name ILIKE '%<value>%'
)
OR EXISTS (
SELECT s3.id
FROM "table_2" s3
WHERE s3.signature_id = t.id
AND (
s3.first_name ILIKE '%<value>%'
OR s3.last_name ILIKE '%<value>%'
OR s3.phone ILIKE '%<value>%'
OR s3.email ILIKE '%<value>%'))
OR EXISTS (
SELECT s4.id
FROM "table_3" s4
WHERE s4.signature_id = t.id
AND s4.name ILIKE '%<value>%'
)
)
ORDER BY t.created_at DESC, t.id ASC LIMIT 20;
Du coup, on s'est dit, pourquoi ne pas tout mettre à plat ?
Afin de tester un potentiel gain avec cette méthode, nous avons créée une table sur notre replica. Cette table contient seulement les données agrégées nécessaires à la requête et issues de 4 tables différentes.
Nous y avons ajouté les index nécessaires permettant de répondre aux différents besoins utilisateurs.
Cette technique nous a permis d'avoir un gain de performance énorme ! Certaines requêtes passaient de plusieurs dizaines de secondes à moins d'une milliseconde malgré la volumétrie de la table (plusieurs dizaines de millions d'entrées) !
Cependant, malgré cette nette amélioration, cette solution amenait une problématique sur laquelle nous n'avions que très peu de recul à ce moment là : comment mettre à jour cette table dans un délai raisonnable ? On aurait pu mettre en place des Triggers, mais nous n'avions aucune connaissance sur la gestion de la concurrence qui en découlait, et au vu du timing assez serré, nous avons fait le choix de ne garder cette solution qu'en cas de dernier recours. En effet, nous souhaitons dans la mesure du possible dans nos implémentations ne pas ajouter de complexité qui pourrait être évitée (le coût de maintenance et de dilution de la compétence est souvent important, sans parler du risque d'avoir des edge cases qui n'ont pas été vus à la conception).
3ème et dernière approche - les index
Comme indiqué au dessus, nous aurions pu nous pencher sur les index en premier. Nous ne l'avons pas fait, car nous avions déjà fait ce travail quelques mois auparavant, lorsque nous sommes passés d'un MariaDB à un PostgreSQL en terme de base de données.
Du coup, nous avons pensé à ce moment là que le problème majeur ne pas pouvait venir de là, surtout connaissant l'ensemble du travail fournis et les résultats à l'époque (la confiance n'empêche pas la vérification, vieille adage qui aurait pu porter ses fruits ici).
Cependant, nous étions arrivés à un stade où il nous fallait des résultats rapidement. L'insatisfaction client ne cessait d'augmenter, et les problèmes de s'accumuler.
Travaillant sur un réplica en mode sandbox, on s'est dit "Bon, pourquoi ne pas essayer les index, de toutes manières au point où l'on en est, au moins on sera fixé !". (Merci à la team SRE pour ça d'ailleurs)
On a donc regardé le code, la structure des tables (dont la principale qui gère les procédures), et on a vu un premier truc étrange... L'index de recherche défini au niveau d'une table ne matchait pas vraiment le code. Non pas que les champs choisis étaient mauvais ou incorrects, mais ils n'étaient pas du tout définis dans le bon ordre, et donc ne matchaient avec quasiment aucune de nos conditions 🤔 ...
Sur le clone de la base de données, nous avons décidé de supprimer l'index en place, pour en recréer un autre plus cohérent avec notre code. Nous avons ensuite lancé la requête la plus longue que nous ayons identifiés pour voir la différence. Résultat : nous sommes passés pour certaines requêtes d'un timeout à un résultat en 7 ou 8 secondes 💪 !
Suite à cette nette amélioration, nous avons encore réussi à améliorer légèrement le résultat en réorganisant plus intelligemment nos conditions dans la clause WHERE en fonction des paramètres de recherche les plus récurrents, mais également en fonction de leur type. Un index sur un champs de type integer est plus performant qu'un index sur un champs de type text, par exemple.
Ci-dessous, un aperçu visuel du gain de performance que nous avons obtenu :
💡 les graphes proviennent de notre environnement de staging, mais les gains ont été les mêmes sur la prod. Nous n'avons malheureusement pas pris de captures à l'époque ...
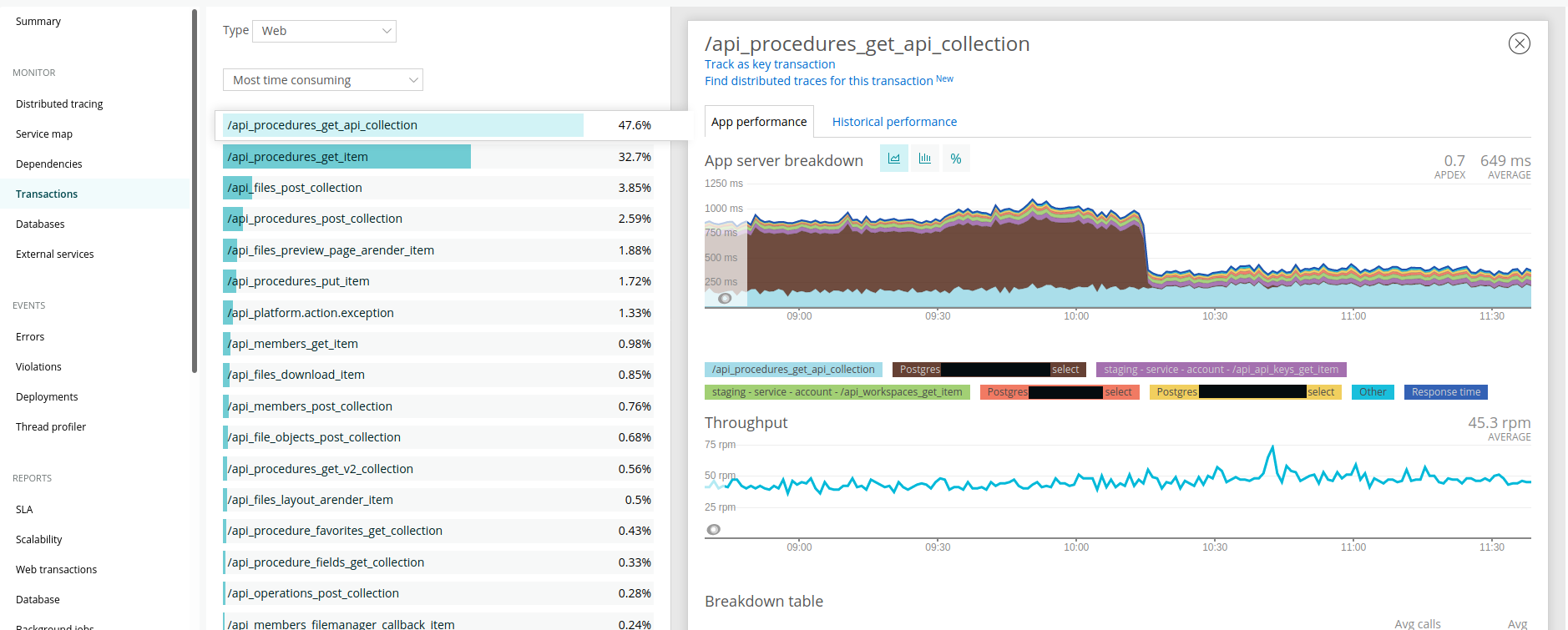
Gain au niveau de la route GET /procedures
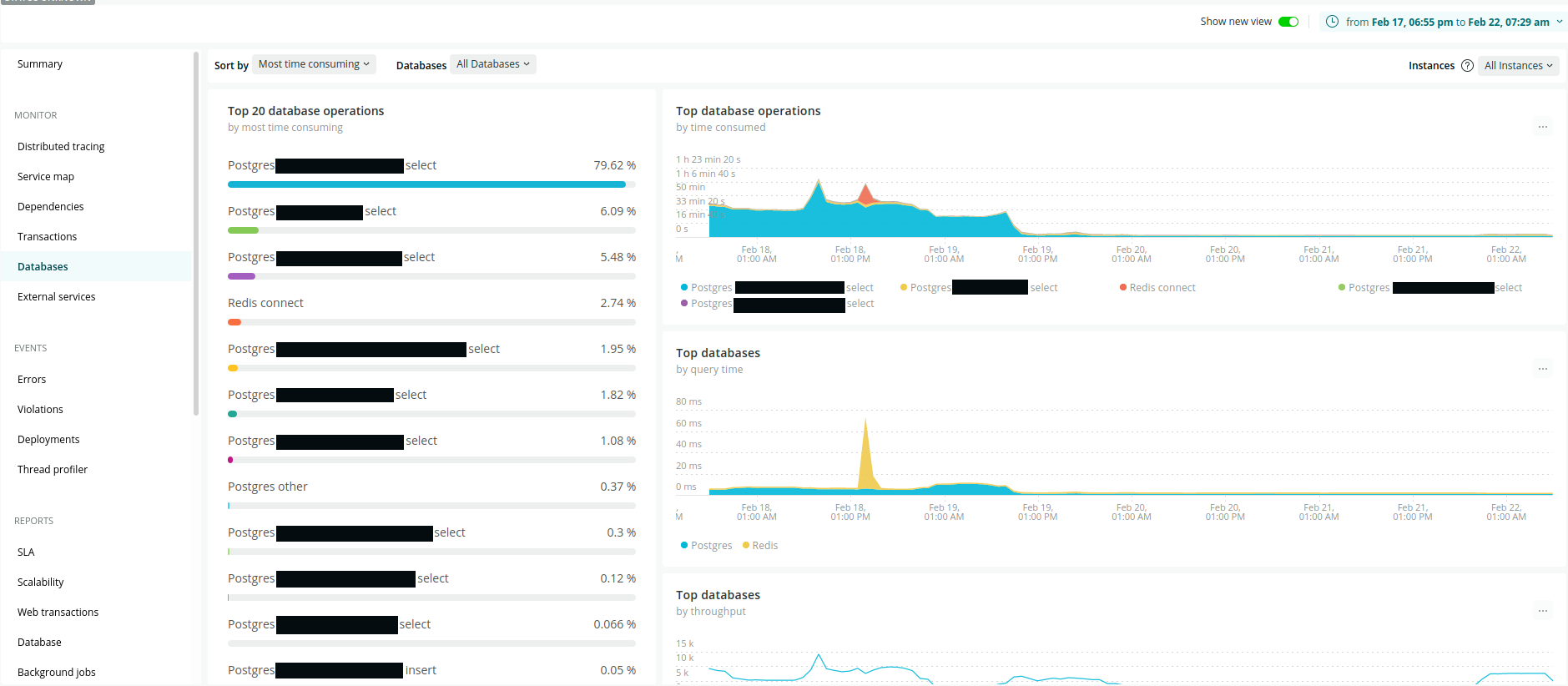
Gain de performance au niveau de la base de données
Que peut-on en dire et qu'a t-on appris ?
On ne va pas se mentir, le sujet n'était pas des plus sexy de prime abord. Mettre le nez dans des requêtes SQL assez complexes, appréhender le code générique coté backend qui permettait de générer ces dernières et tenter de comprendre tant bien que mal le charabia analytique que nous retournait la commande EXPLAIN ANALYZE n'a pas toujours été une partie de plaisir.
Néanmoins, travailler sur ce sujet a été très instructif, tant au niveau de l'analyse d'une requête SQL par le moteur, qu'au niveau de l'anticipation des problèmes de volumétrie qui peuvent survenir, comme nous en avons eu.
Les outils que nous avions mis en place tels que Graylog, NewRelic ou encore PgHero, nous ont été d'une grande d'aide. Sans compter également ceux trouvés en ligne tels que https://explain.depesz.com/ , ou encore https://tatiyants.com/, pour nous aider à comprendre certaines analyses de requêtes. Ils nous ont permis de voir les améliorations à chaque itération, mais également de pouvoir monitorer nos requêtes et déceler celles anormalement longues (même encore maintenant).
Nous sommes conscients que la solution retenue au final n'est pas la meilleure. Certes, nous avons obtenu un gros gain de performance, mais certaines de nos requêtes retournent encore un résultat au bout de plusieurs secondes, voir dizaines de secondes parfois... Néanmoins, avant nous en avions beaucoup et l'impact pour certains clients n'était pas acceptable, d'autant maintenant ce sont des cas à la marge qui surviennent dans des contextes très limités.
Pourquoi nous avons décidé de nous arrêter là? C'est le contexte, qui nous a décidé à ne pas aller plus loin dans l'optimisation. La prochaine version était déjà en préparation, nous nous sommes dit que les résultats obtenus étaient plus qu'acceptables et nous n'avions plus de clients gênés par ces lenteurs. Cependant, nous avons quand même pu remonter certaines problématiques et solutions à l'équipe travaillant sur la version suivante pour qu'ils puissent anticiper ce genre de problème.
Par ailleurs, nous avons conscience que faire de la recherche de données au sein d'une base de données est possible, mais n'est pas optimal. Nous aurions pu construire une table dédiée à la recherche en y agrégeant des données, mais une solution telle qu'un Elasticsearch ou un Algolia est préférable sur le long terme. Après, comme toutes solutions techniques, il est préférable de peser le pour et le contre, car de telles solutions, malgré le gain qu'elles apportent, peuvent être lourdes à mettre en œuvre et/ou coûteuses !
*Une nouvelle version était en développement